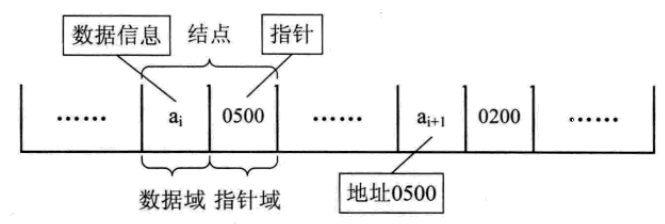
每个数据元素ai与其直接后继数据元素ai+1之前的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接 后继的信息(即直接 后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
n个结点(ai的存储映像)链结成一个链表,即为线性表(a1,a2,……an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫单链表。
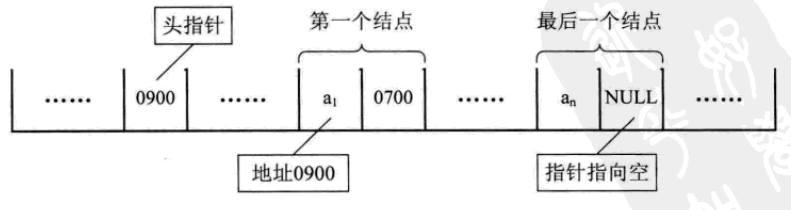
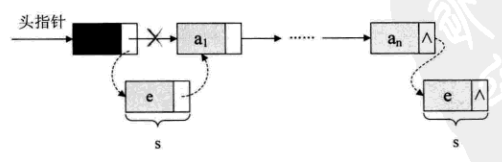
有时,我们为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。
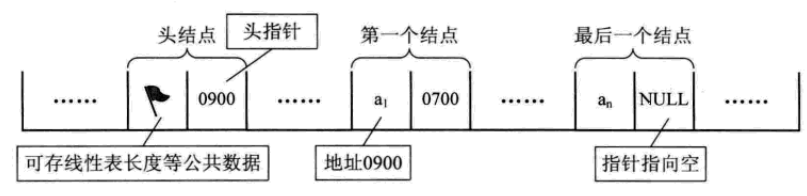
- 头指针与头结点的异同

2. 线性表链式存储结构代码描述
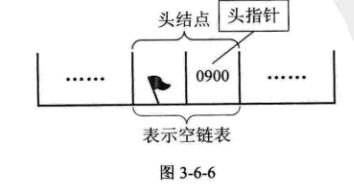
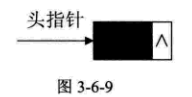
若线性表为空表,则头结点的指针域为“空”
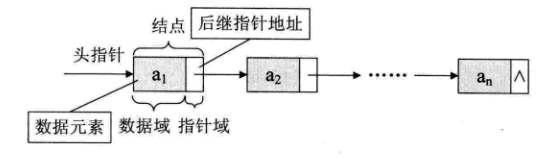
若带有头结点的单链表,则如下图

空链表如下图
单链表中,我们在C语言中可用结构指针来描述
/*线性表的单链表存储结构*/
typedef struct Node
{
ElemType data;
struct Node *next;
}Node;
typedef struct Node *LinkList; /*定义LinkList*/结点由存放数据元素的数据域和存放后继结点地址的指针域。
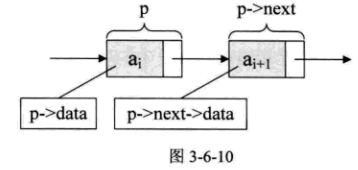
假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data来表示,p->data的值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next的值是一个指针。 p->next指向ai+1的指针。也就是说, 如果p->data = ai, 那么p->next->data = ai+1
3. 单链表的读取
获得链表的第i个数据的算法思路
- 声明一个结点p指向链表第一个结点,初始化j从1开始;
- 当j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点,j累加1;
- 若到链表末尾p为空,则说明第i个元素不存在
- 否则查找成功, 返回结点p的数据
实现代码算法如下:
/*初始条件: 顺序线性表L已存在,1<=i<=ListLength(L)*/
/*操作结构:用e返回L中第i个数据元素的值*/
Status GetElem(LinkList L, int i, ElemType *e)
{
int j;
LinkList p; /*声明一结点p*/
p = L->next; /*让p指向链表L的第一个结点*/
j = 1; /*j为计数器*/
while (p && j<i) { /*p不为空或者计数器j还没有等于i时,循环继续*/
p = p->next; /*让p指向下一个结点*/
++j;
}
if (!p || j>i)
return ERROR; //第i个元素不存在
*e = p->data; //取第i个元素的数据
return OK;
}说白了,就是从头开始找,直到第i个元素为止。由于这个算法的时间复杂度取决于i的位置, 当i=1时,则不需遍历,第一个就取出数据了,而当i=n时则遍历n-1次才可以。因此最坏的情况的时间复杂度是o(n).
4. 单链表的插入
假设存储元素e的结点为s, 要实现结点p, p->next和s之间的逻辑关系的变化,只需将结点s插入到结点p和p->next之间即可。
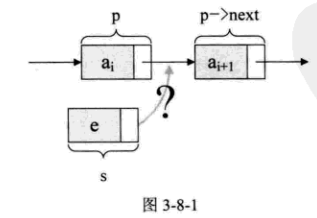
只需要让s->next和p->next的指针做一点改变。
s->next=p->next;
p->next=s;让p的后继结点改成s的后继结点,再把结点s变成p的后继结点
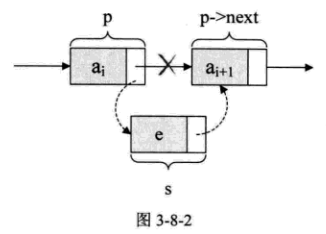
插入s后
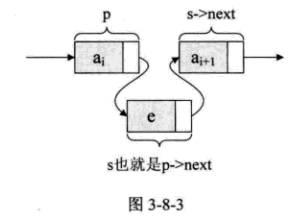
对于单链表的表头和表尾的特殊性况,操作是相同的
单链表第i个数据插入结点的算法思路:
- 声明一结点p指向链表第一个结点,初始化j从1开始;
- 当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j累加1;
- 若到链表末尾p为空,则说明第i个元素不存在;
- 否则查找成功,在系统中生成一个空结点s;
- 将数据元素e赋值给s->data;
- 单链表的插入标准语句s->next = p->next; p->next=s;
- 返回成功
代码描述:
/**
* @brief 单链表的插入
* 初始条件,顺序线性表L已经存在, 1<=L<=ListLength(L)
* 操作结果: 在L中第i个位置之前插入新的数据元素e,L的长度加1
*
*/
Status ListInsert(LinkLit *L, int i, ElemType e)
{
int j;
LinkList p, s;
p = *L;
j = 1;
while( p && j<i) {//寻找第i个结点
p = p->next;
++j;
}
if(!p || j>i)
return ERROR; //第i个元素不存在
s = (LinkList) malloc(sizeof(Node)); //生成新结点(C标准函数)
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}这里我们用了malloc C语言的标准函数,它作用为生成一个新的结点。其类型与Node一样。
5. 单链表的删除
设存储 元素ai的结点为q, 要实现将结点q删除单链表的操作,其实就是将它的前继结点的指针绕过,指向它的后继结点即可。
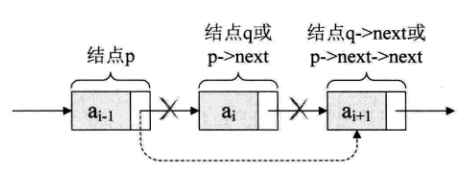
实际上就一步, p->next = p->next->next, 用q来取代p->next,即是 q=p->next; p->next = q->next;
单链表第i个数据删除结点的算法思路:
- 声明一结点p指向链表的第一个结点, 初始化j从1开始;
- 当j<i时,就遍历链表,让 p的指针向后移动,不断指向下一个结点,累加j
- 若到链表末尾p为空,则说明第i个元素不存在
- 否则查找成功, 将欲删除的结点p->next赋值给q;
- 单链表的删除标准语句:p->next = q->next;
- 将q结点中的数据赋值给e, 作为返回;
- 释放q结点;
- 返回成功
代码:
Status ListDelete(LinkList *L, int i, ElemType *e)
{
int j;
LinkList p, q;
p = *L;
j = 1;
while (p->next && j<i) {
p = p->next;
++j;
}
if (!(p->next) || j>i) {
return ERROR;
}
q = p->next;
p->next = q->next;
*e = q->data;
free(q);
return OK;
}C语言标准函数free, 作用是让系统回收一个Node结点,释放内存。
单链表的插入与删除,时间复杂度都是O(n)。
6. 单链表的整表创建
顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。单链表则不一样:
单链表整表创建的算法思路:
- 声明一结点p和计数器变量i;
- 初始化一空链表L;
- 让L的头结点的指针指向NULL, 即建立一个带头结点的单链表;
- 循环:
- 生成一新结点赋值给p;
- 随机生成一数字赋值给p的数据域p->data;
- 将p插入到头结点与前一新结点之间。
/**
* @brief 单链表创建整表, 头插法
*
*/
void CreateListHead(LinkList *L, int n)
{
LinkList p;
int i;
srand(time());
*L = (LinkList) malloc (sizeof(Node));
(*L)->next = NULL;
for (i=0; i<n; i++) {
p = (LinkLIst) malloc(sizeof(Node));
p->data = rand()%100+1;
p->next = (*L)->next;
(*L)->next = p;
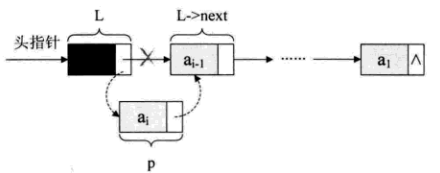
}
}
/**
* @brief 随机产生n个元素的值,建立带表头结点的单链线性表L(尾插法)
*
* @param L
* @param n
*/
void CreateLIstTail(LinkList *L, int n)
{
LinkList p, r;
int i;
srand(time(0));
*L = (LinkList) malloc(sizeof(Node));
r = *L; //r为指向尾部的结点
for (i=0; i<n; i++) {
p = (Node *) moalloc(sizeof(Node));
p->data = rand()%100 +1; //随机生成100以内的数字
r->next = p;
r = p;
}
r->next = NULL;
}注意:L与r的关系,L是指整个单链表,而r是指向尾结点的变量,r会随着循环不断地变化结点, 而L则是随着循环增长为一个多结点的链表。
这里需要解释一下,r->next = p;的意思, 其实就是将刚才的表尾终端结点r的指镇里指向新结点p
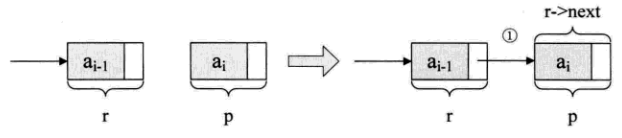
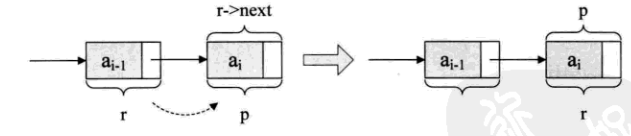
r = p是什么意思?
本来r是在ai-1元素的结点,可现在它已经不是最后的结点了,现在最后的结点是ai,所以应该要让将p结点这个最后的结点赋值给r。此时r又是最终的尾结点了。
7。 单链表的整表删除
算法思路:
- 声明一个结点p和q;
- 将第一结点赋值给p;
- 循环:
- 将下一结点赋值给q;
- 释放p;
- 将q赋值给p
代码:
Status ClearList(LinkList *L)
{
LinkList p, q;
p = (*L)->next;
while(p) {
q = p->next;
free(p);
p = q;
}
(*L)->next = NULL; //头结点指针域为空
return OK;
}8. 单链表结构与顺序存储结构优缺点

结论:
- 若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。若要频繁插入和删除时, 宜采用单有结构。
- 当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,这样可以不需要考虑存储空间大小问题。