1. 前言
Elasticsearch社区中经常看到慢查询问题:“你能帮我看看Elasticsearch的响应时间吗?”或者是:“我的ES查询耗时很长,我该怎么做?”包含但不限于:Nested慢查询、集群查询慢、range查询慢等问题。
2. 两个维度
每当我们得到这些类型的问题时,我们首先要深入研究两个主要方面:
- 配置维度 – 查看当前系统资源和默认Elasticsearch选项。
- 开发维度 – 查看查询,其结构以及要搜索的数据的映射(Mapping)。
我们将首先关注开发方面的问题。 我们将获得慢查询,讨论DSL查询语言,并查看有助于改进Elasticsearch查询的小型常规选项。
3. 开发维度
3.1 你的查询有多慢?
Elasticsearch中有两个版本的慢速日志:索引慢速日志(index slow logs )和搜索慢速日志( search slow logs)。 默认情况下,所有版本的Elasticsearch都会关闭慢速日志,因此您必须对群集设置和索引设置进行一些更新。有关日志记录级别的更多信息,参考:https://stackoverflow.com/questions/2031163/when-to-use-the-different-log-levels
搜索慢速日志根据搜索阶段分解为单独的日志文件:获取(fetch)和查询(query)。
现在我们在日志中有结果,我们可以拉入一个条目并将其分开。
[2018-05-21T12:35:53,352][DEBUG ][index.search.slowlog.query]
[DwOfjJF] [blogpost-slowlogs][4] took[1s], took_millis[0], types[],
stats[], search_type[QUERY_THEN_FETCH], total_shards[5],
source[{"query":{"match":{"name":{"query":"hello world",
"operator":"OR","prefix_length":0,"max_expansions":50,
"fuzzy_transpositions" :true,"lenient":false,"zero_terms_query":
"NONE","boost":1.0}}},"sort":[{"price": {"order":"desc"}}]}],
在这里,您看到:
1 日期
2 时间戳
3 日志级别
4 慢速类型
5 节点名称
6 索引名称
7 分片号
8 时间花费
9 查询的主体(_source>)
一旦我们获得了我们认为花费的时间太长的查询,我们就可以使用一些工具来分解查询:
- 工具1:Profile API
Profile API提供有关搜索的信息页面,并分解每个分片中发生的情况,直至每个搜索组件(match/range/match_phrase等)的各个时间。 - 工具2:Kibana profiling 工具
这与_profileAPI密切相关。 它提供了各个搜索组件的完美的可视化效果表征各个分解阶段以及各阶段查询的时间消耗。 同样,这允许您轻松选择查询的问题区域。
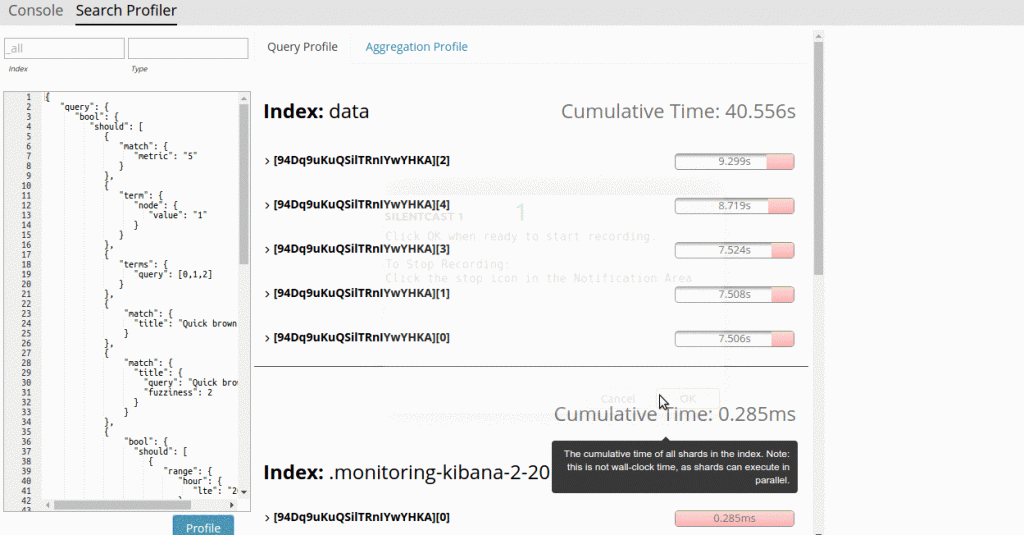
3.2 Elasticsearch的查询原理
现在我们已经确定了一个很慢的查询,我们通过一个分析器profile来运行它。 但是,查看单个组件时间结果并未使搜索速度更快。 怎么办?
通过两个阶段(下面)了解查询的工作原理,允许您以从速度和相关性方面获得Elasticsearch最佳结果的方式重新设计查询。
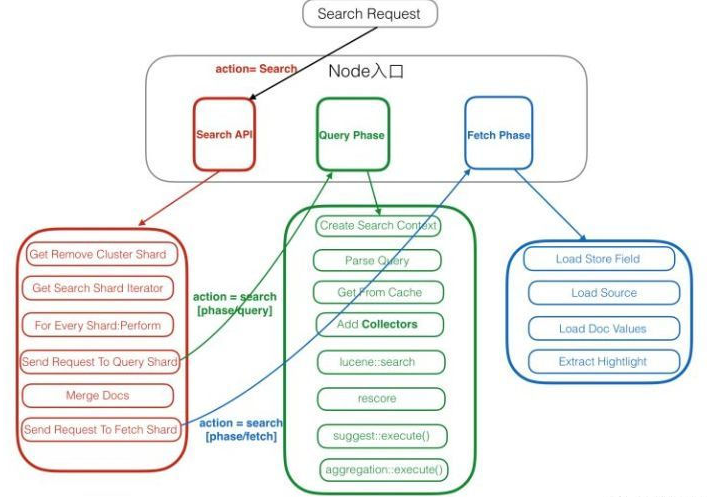
3.2.1 Query阶段
- 路由节点接受该查询。
- 路由节点识别正在搜索的索引(或多个索引)。
- 路由节点生成一个节点列表,其中包含索引的分片(主要和副本的混合)。
- 路由节点将查询发送到节点(上一步节点列表列出的节点)。
- 节点上的分片处理查询。
- 查询(默认情况下)对前10个文档进行评分。
- 该列表将发送回路由节点。
3.2.2 fetch阶段
获取阶段由路由节点开始,路由节点向分片发出对前10个文档的请求。 (可能是包含最高得分文档的一个分片,或者它们可能分散在多个分片中)。路由节点确定每个分片发送的50个(5个分片×10个结果)结果中的前10个文档。
返回列表后,主节点会在查询响应的_hits部分中显示文档。
3.3 filter过滤器查询优化
Elasticsearch根据您提供的参数对查询结果进行评分。如果您有快速搜索需求但结果不是您要查找的结果,则整个搜索都是浪费时间。那么,你如何加快搜索速度?
3.3.1 查询时,使用query-bool-filter组合取代普通query
提高搜索性能的一种方法是使用过滤器:
默认情况下,ES通过一定的算法计算返回的每条数据与查询语句的相关度,并通过score字段来表征。但对于非全文索引的使用场景,用户并不care查询结果与查询条件的相关度,只是想精确的查找目标数据。此时,可以通过query-bool-filter组合来让ES不计算score,并且尽可能的缓存filter的结果集,供后续包含相同filter的查询使用,提高查询效率。
filter原理推荐阅读:吃透 | Elasticsearch filter和query的不同
3.4 其他优化
3.4.1 避免使用script查询
避免使用脚本查询来计算匹配。 推荐:建立索引时存储计算字段。
3.4.2 避免使用wildcard查询
主要原因: wildcard类似mysql中的like,和分词完全没有了关系。
出现错误: 用户输入的字符串长度没有做限制,导致首尾通配符中间可能是很长的一个字符串。 后果就是对应的wildcard Query执行非常慢,非常消耗CPU。
根本原因: 为了加速通配符和正则表达式的匹配速度,Lucene4.0开始会将输入的字符串模式构建成一个DFA (Deterministic Finite Automaton),带有通配符的pattern构造出来的DFA可能会很复杂,开销很大。
可能的优化方案:wildcard query应杜绝使用通配符打头,实在不得已要这么做,就一定需要限制用户输入的字符串长度。
最好换一种实现方式,通过在index time做文章,选用合适的分词器,比如nGram tokenizer预处理数据,然后使用更廉价的term query来实现同等的模糊搜索功能。
对于部分输入即提示的应用场景,可以考虑优先使用completion suggester, phrase/term/suggeter一类性能更好,模糊程度略差的方式查询,待suggester没有匹配结果的时候,再fall back到更模糊但性能较差的wildcard, regex, fuzzy一类的查询。
3.4.3 合理使用keyword类型
ES5.x里对数值型字段做TermQuery可能会很慢。在ES5.x+里,一定要注意数值类型是否需要做范围查询,看似数值,但其实只用于Term或者Terms这类精确匹配的,应该定义为keyword类型。
典型的例子就是索引web日志时常见的HTTP Status code。
详尽原理参考:https://elasticsearch.cn/article/446
3.4.4 控制字段的返回
- 数据建模规划的时候,在Mapping节点对于仅存储、是否构建倒排索引通过enabled、index参数进行优化。
- _source控制返回,不必要的字段不需要返回,举例:采集的原文章详情内容页,根据需要决定是否返回。
3.4.5 让Elasticsearch干它擅长的事情
在检索/聚合结果后,业务系统还有没有做其他复杂的操作,花费了多少时间?这块是最容易忽视的时间耗费担当。Elasticsearch显然更擅长检索、全文检索,其他不擅长的事情,尽量不要ES处理。比如:频繁更新、确保数据的ACID特性等操作。
4. 配置维度
4.1 节点职责明晰
区分:路由节点、数据节点、候选主节点。
区分路由节点/数据节点/候选主节点的主要优点是:
- 由于路由节点减少了搜索和聚合的压力,因此数据节点上的内存压力略有降低;
- “智能路由”——因为他们知道所有数据存在的地方,他们可以避免额外的跳跃;“智能路由”——因为他们知道所有数据存在的地方,他们可以避免额外的跳跃;
- 从架构上讲,将路由节点用作集群的访问点非常有用,因此您的应用程序无需了解详细信息。
尽量将主节点与数据节点分开,因为它将减少所有群集的负载。
以下时间开始考虑专用主节点:
- 群集大小开始变得难以驾驭,可能像10个节点或更高?
- 您会看到由于负载导致集群不稳定(通常由内存压力引起,导致长GC,导致主节点暂时从集群中退出)您会看到由于负载导致集群不稳定(通常由内存压力引起,导致长GC,导致主节点暂时从集群中退出)
分离主节点的主要目的:
使“主节点的职责”与负载隔离,因为高负载可能导致长GC,从而导致集群不稳定。
分离主节点后,一个高负载的集群只会影响数据节点(显然仍然不好),但能保证主节点稳定,一旦集群超载,基本上专门的主节点给你喘息的空间,而不是整个集群走向崩溃。另外,与数据节点相比,主节点通常可以非常“轻”。几GB的RAM,中等CPU,普通磁盘等或许就能满足需求(需要根据实际业务场景权衡)。
推荐阅读:http://t.cn/E7HM4ML
4.2 分配合理的堆内存
搜索引擎旨在快速提供答案。 为此,他们使用的大多数数据结构必须驻留在内存中。 在很大程度上,他们假设你为他们提供了足够的记忆。 如果不是这种情况,这可能会导致问题 – 不仅仅是性能问题,还有集群的可靠性问题。
合理的堆内存大小配置建议: 宿主机内存大小的一半和31GB,取最小值
4.3 设置合理的分片数和副本数
shard数量设置过多或过低都会引发一些问题。shard数量过多,则批量写入/查询请求被分割为过多的子写入/子查询,导致该index的写入、查询拒绝率上升;对于数据量较大的index,当其shard数量过小时,无法充分利用节点资源,造成机器资源利用率不高 或 不均衡,影响写入/查询的效率。
对于每个index的shard数量,可以根据数据总量、写入压力、节点数量等综合考量后设定,然后根据数据增长状态定期检测下shard数量是否合理。
腾讯基础架构部数据库团队的推荐方案是:
- 对于数据量较小(100GB以下)的index,往往写入压力查询压力相对较低,一般设置3~5个shard,副本设置为1即可(也就是一主一从,共两副本)
- 对于数据量较大(100GB以上)的index:一般把单个shard的数据量控制在(20GB~50GB)
让index压力分摊至多个节点:可通过index.routing.allocation.totalshardsper_node参数,强制限定一个节点上该index的shard数量,让shard尽量分配到不同节点上;
综合考虑整个index的shard数量,如果shard数量(不包括副本)超过50个,就很可能引发拒绝率上升的问题,此时可考虑把该index拆分为多个独立的index,分摊数据量,同时配合routing使用,降低每个查询需要访问的shard数量。
4.4 设置合理的线程池和队列大小
节点包含多个线程池,以便改进节点内线程内存消耗的管理方式。 其中许多池也有与之关联的队列,这允许保留挂起的请求而不是丢弃。
search线程——用于计数/搜索/推荐操作。 线程池类型为fixed_auto_queue_size,大小为int((available of available_ * 3)/ 2)+ 1,初始队列大小为1000。
5.X版本之后,线程池设置是节点级设置。因此,无法通过群集设置API更新线程池设置。
查看线程池的方法: GET /_cat/thread_pool
4.5 硬件资源的实时监控
排查一下慢查询时间点的时候,注意观察服务器的CPU, load average消耗情况,是否有资源消耗高峰,可以借助:xpack、cerbero或者elastic-hd工具查看。
当您遇到麻烦并且群集工作速度比平时慢并且使用大量CPU功率时,您知道需要做一些事情才能使其再次运行。 当Hot Threads API可以为您提供查找问题根源的必要信息。 热线程hot thread是一个Java线程,它使用高CPU量并执行更长的时间。
Hot Threads API返回有关ElasticSearch代码的哪一部分是最耗费cpu或ElasticSearch由于某种原因而被卡住的信息。
热线程使用方法: GET /_nodes/hot_threads
5 小结
回答文章开头的问题:——为什么Elasticsearch查询变得这么慢了?
和大数据量的业务场景有关,您可以通过几个简单的步骤优化查询:
- 启用慢速日志记录,以便识别长时间运行的查询
- 通过
_profiling API运行已识别的搜索,以查看各个子查询组件的时间通过_profiling API运行已识别的搜索,以查看各个子查询组件的时间 - 过滤,过滤,过滤过滤,过滤,过滤
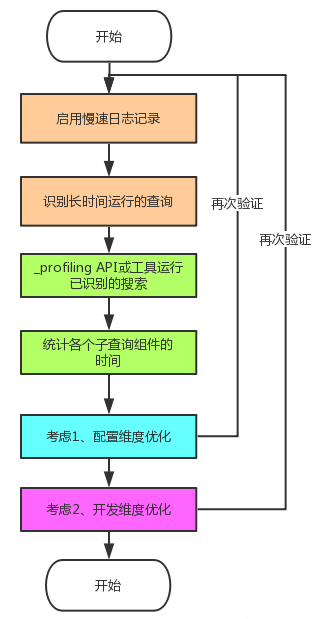
Elasticsearch优化非一朝一夕之功,需要反复研究、实践甚至阅读源码分析。本文综合了国外、国内很多优秀的实践建议,核心点都已经实践验证可行