1、 Redis到底是单线程还是多线程
Redis6.0 版本之前的单线程指的是其网络I/O和键值对读写是由一个线程完成的
Redis6.0引入多线程指的是网络请求过程采用了多线程,而键值对读写命令仍然是单线程处理的,所以Redis依然是并发安全的
也就是只有网络请求模块和数据操作模块是单线程的,而其它的持久化、集群数据同步等,其实是由额外的线程执行的
2. Redis单线程为什么还能这么快
命令执行基于内存操作,一条命令在内存里操作的时间是几十纳秒
命令执行是单线程操作,没有线程切换开销
基于IO多路复用机制提升Redis的I/O利用率
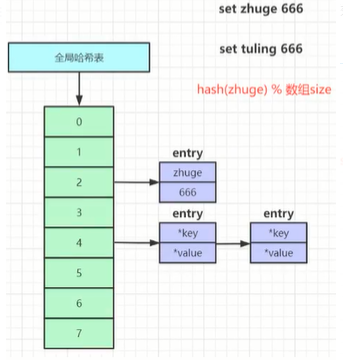
高效的数据存储结构: 全局hash表以及多种高效数据结构, 比如: 跳表、压缩列表、链表等等
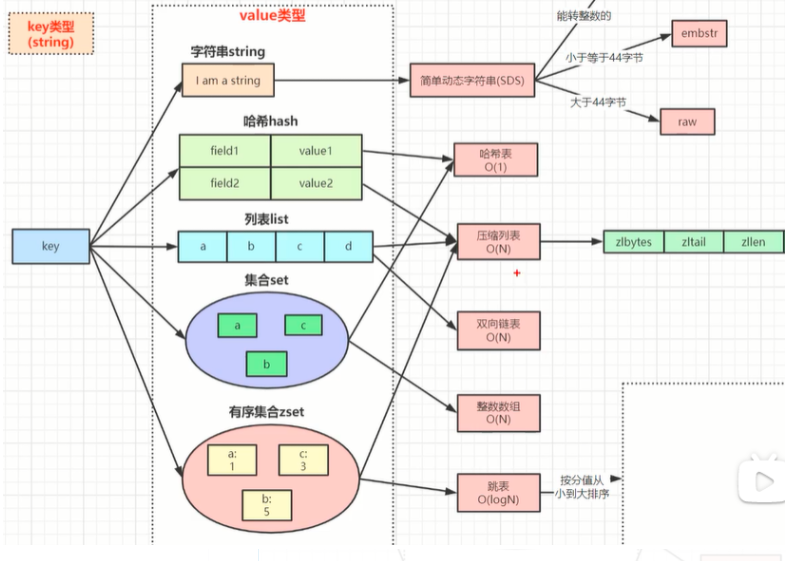
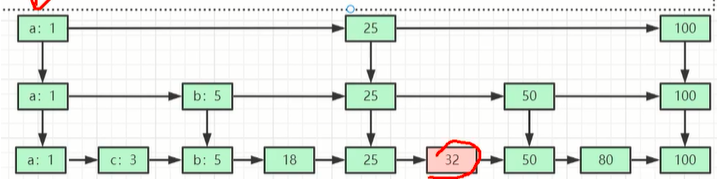
3. Redis底层数据是如何用跳表来存储的
将有序链表改造为支持近似折半查找算法,可以进行快速的插入、删除、查找操作
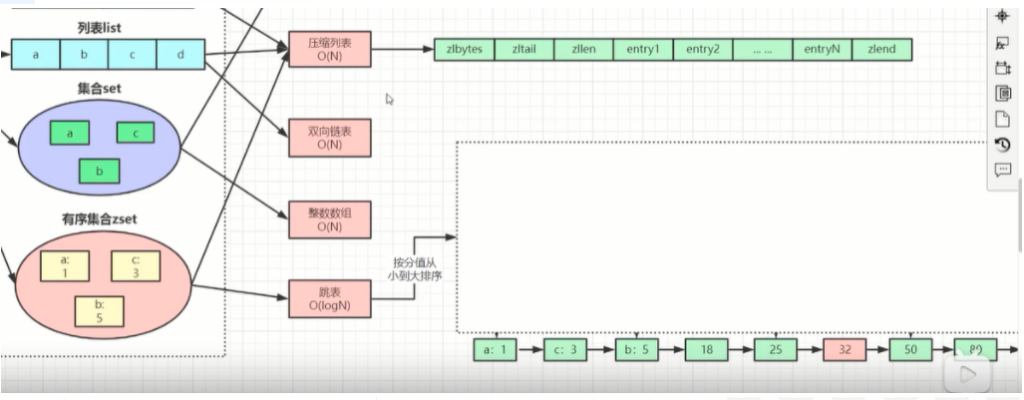
跳表的结构如下图
4. Redis Key过期了为什么内存没释放
你在使用Redis时,肯定经常使用SET命令
SET除了可以设置key-value之外,还可以设置key的过期时间,就像下面这样:
127.0.0.1:6379> SET tuling zhuge EX 120
OK
127.0.0.1:6379> TTL tuling
(integer) 117此时如果你想修改key的值,但只是单纯地使用SET命令,而没有加上过期时间的参数,那这个key的过期时间将会被擦除
127.0.0.1:6379> SET tuling zhuge666
OK
127.0.0.1:6379> TTL tuling //key永远不过期了
(integer) -1导致这个问题的原因在于: SET命令如果不设置过期时间,那么Redis会自动擦除这个key的过期时间。
如果你发现redis的内存持续增长,而且很多key原来设置了过期时间,后来发现过期时间丢失了,很有可能是因为这个原因导致的。
这时你的redis中就会存在大量不过期的key, 消耗过多的内存资源。
所以, 你在使用SET命令时,如果刚开始就设置了过期时间,那么之后修改这个key,也务必要加上过期时间的参数,避免过期时间丢失问题。
Redis对于过期key的处理一般有惰性删除和定时删除两种策略。
1)惰性删除: 当读、写一个已经过期的key时,会触发惰性删除策略,判断key是否过期, 如果过期了直接删除掉这个key
2) 定时删除: 由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期(默认每100ms)主动淘汰一批已经过期的key, 这里一批只是部分key, 所以可能会出现部分key已经过期但还没有被清理掉的情况,导致内存并没有被释放。
5. Redis Key设置过期时间为什么被Redis主动删除了
当Redis已用内存超过maxmemory限定时,触发主动清理策略
主动清理策略在redis4.0之前一共实现了6种内存淘汰策略,在4.0之后,又增加了2种策略。共8种:
1)针对设置了过期时间的key做处理
a. volatitle-ttl: 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
b. volatitle-random: 就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
c. volatitle-lru: 会使用LRU(最近最少使用)算法筛选设置了过期时间的键值对删除。
d. volatitle-lfu: 会使用LFU(最不经常使用)算法筛选设置了过期时间的键值对删除。
2)针对所有的key做处理:
a. allkeys-random: 从所有键值对中随机选择并删除数据
b. allkeys-lru: 使用LRU算法在所有数据中进行筛选删除。
c. allkeys-lfu: 使用LFU算法在所有数据中进行筛选删除。
3) 不处理
a. noeviction 不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息“(error) OOM command not allowed when used memory”, 此时Redis只响应读操作。
6. Redis淘汰的算法LRU与LFU区别
LRU算法(Least Recently Used 最近最少使用): 淘汰很久没有被访问过的数据,以最近一次访问时间作为参考
LFU算法(Least Frequently Used最不经常使用): 淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
绝大多数情况我们都可以用LRU策略,当存在大量的热点缓存数据时,LFU可能更好点。
7.删除Key的命令会阻塞Redis吗?
DEL
格式: DEL key [key…]
删除给定的一个或多个key. 不存在的key会被忽略
可用版本: >= 1.0.0
时间复杂度: O(N), N为被删除的key的数量。删除单个字符串类型的key,时间复杂度为O(1)。 删除单个列表, 集合, 有序集合或哈希表类型的key, 时间复杂度为O(N), N为以上数据结构内的元素数量。
返回值: 被删除key的数量
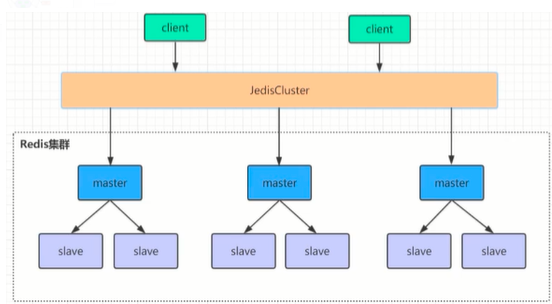
8. Redis主从、哨兵、集群架构优缺点比较
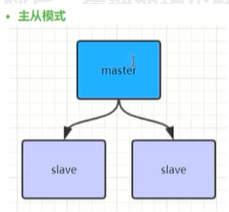
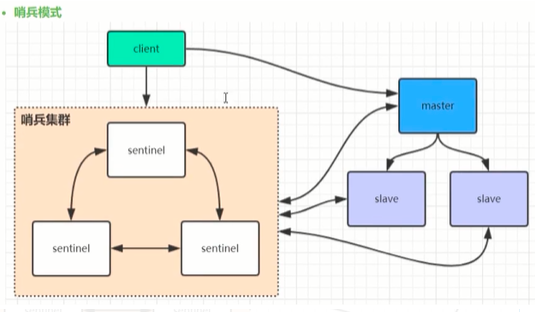
Redis单节点最多不超过10G,太多会影响数据的恢复。 3-5G会好一点
在Redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异常,则会做主从切换, 将某一台slave作为master, 哨兵的配置略微复杂, 并且性能和高可用性能等方面表现一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持很高的并发,且单个主节点内存也不宜设置过大,否则会导致持久化文件过大,影响数据恢复或主从同步的效率。
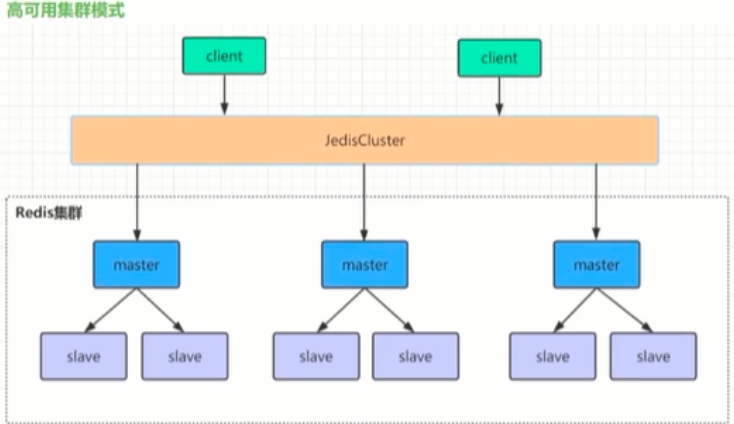
Redis集群是一个由多个主从节点群组成的分布式服务器群, 它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵,也能完成节点转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点),redis集群的性能和高可用性均优于之前版本的哨兵模式, 且集群配置非常简单。
9. Redis集群数据Hash分片算法是怎么回事
Redis Cluster将所有数据划分为16384个slot(槽位),每个节点负责其中一部分槽位。槽位的信息存储于每个节点中。当Redis Cluster的客户端来连接集群时,它也会得到一份集群槽位配置信息并将其缓存在客户端本地。这样客户端要查找某个key时,可以根据槽位定位算法定位到目标节点
槽位定位算法
Cluster默认会对key值使用CRC16算法进行hash得到一个整数值,然后用这个整数值对16384进行取模来得到具体槽位。
HASH_SLOT=CRC16(key) mod 16384
再根据槽位值和Redis节点的对应关系就可以定位到key具体是落在哪个Redis节点上的。